- Thrust
- Простейшее преобразование на примере сложения векторов
- Занятие 8. Программирование на CUDA C. Часть 4.
- Сложение векторов в cuda
- Технологии для разработки на основе CUDA
- Thrust
- Простейшее преобразование на примере сложения векторов
- CUDA: Как работает GPU
- Вычислительная модель GPU:
- CUDA и язык C:
- CUDA host API:
- Понимаем работу GPU:
- Заключение
- Занятие 8. Программирование на CUDA C. Часть 4.
Thrust
Thrust [12] — это библиотека параллельных алгоритмов обработки данных на GPU, представленных в виде векторов, с интерфейсом аналогичным C++ Standard Template Library (STL). Thrust удобен возможностью быстро реализовывать необходимые вычислительные алгоритмы в более простой и читаемой форме, чем явное программирование на CUDA. Библиотека уже содержит реализации некоторых базовых алгоритмов (scan, sort и reduce) и позволяет комбинировать их для составления более сложных схем обработки. С другой стороны, Thrust имеет более высокий уровень абстракции, чем CUDA, и не позволяет разработчику непосредственно управлять GPU на низком уровне, например, разделяемой памятью или синхронизацией нитей. Таким образом, Thrust может лучше всего подходить для GPU-приложений, в которых наиболее важную роль играет скорость разработки и надежность.
Thrust входит в состав CUDA Toolkit 4.0, но может быть также установлен отдельно. Сама библиотека состоит только из заголовочных файлов, и необходимые части кода Thrust будут скомпилированы вместе с целевым приложением.
Простейшее преобразование на примере сложения векторов
Пусть необходимо сложить два вектора и поместить результат в третий вектор. На C++ это тривиально реализуется следующим кодом:
for (int i = 0; i ?include Cthrust / transform . h> ?include Cthrust/functional.h> ?include Ciostream>
X[0] = 10; X[l] = 20; X[2] = 30;
Y[0] = 15; Y[l] = 35; Y[2] = 10;
for (size_t i = 0; i — это библиотечный функтор (о функторах речь пойдет далее) операции сложения двух элементов, параметризованный типом float, который применяется к каждой паре элементов X и Y. Аналогично оператору присваивания, оператор «[ ]» реализует копирование данных из памяти GPU в память хоста, что позволяет легко производить поэлементный доступ. Память GPU, занимаемая векторами, будет автоматически освобождена деструктором вектора при выходе за пределы области видимости, содержащей определения.
Сборка приложения, использующего Thrust ничем не отличается от сборки любого CUDA-приложения:
$ nvcc —02 ex01_vector_addition.си —о ex01_vector_addition
Входной файл должен иметь расширение си. Файл с расширением срр, содержащий расширения языка C++, будет сразу передан CPU-компилятору, который скорее всего вернет ошибки компиляции.
Занятие 8. Программирование на CUDA C. Часть 4.
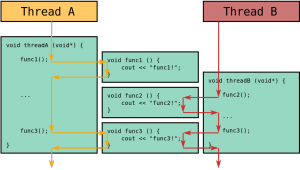


Сложение векторов и сравнение с количеством тредов в памяти
Данный пример довольно прост и демонстрирует реализацию сложения двух векторов, у которых сумма общих нитей не превышает определенное число (в данном случае 10).
Понятное дело, если мы будем использовать N Блоков и 1 тред ( add N , 1 >>>( dev _ a , dev _ b , dev _ c ); ) , то каждый результат с будет равным нулю, кроме первого, поэтому этот код закомментирован, но присутствует в программе в качестве ознакомления с работой блоков и тредов в ядре. В нашем случае результат выполнения программы следующий:

И так до 63 значений, так как подсчет идет с нуля.
Генерация псевдослучайных чисел с использованием CuRand
Генерация псевдослучайных чисел происходит с помощью инструмента curand, который входит в расширение CUDA C.
Библиотека cuRAND предоставляет средства, которые сосредоточены на простой и эффективной генерации псевдослучайных и квазислучайных чисел. cuRAND состоит из двух частей: библиотеки на стороне хоста (CPU) и файла заголовка устройства (GPU). Библиотека на стороне хоста рассматривается как любая другая библиотека: пользователь включает заголовочный файл, #include , чтобы получить объявления функций. Случайные числа могут быть сгенерированы на девайсе или на хосте. Полученные случайные числа сохраняются в глобальной памяти на девайсе. Также пользователь может копировать полученные случайные числа обратно на хост для дальнейшей обработки. Для генерации чисел на хосте вся работа выполняется на хосте, включая их хранение.
Вторая составляющая cuRAND — это заголовочный файл устройства, /include/curand_kernel.h . Этот файл определяет функции генератора случайных чисел. Пользовательский код может включать этот заголовочный файл, а написанные пользователем ядра могут затем вызывать функции устройства, определенные в файле заголовка. Это позволяет создавать случайные числа и немедленно использовать их.
Ниже будет код, демонстрирующий работу данного инструмента:
Как было сказано, первоначально объявляются заголовочные файлы, после чего прописывается стандартная С++ директива define с макросом MAX 100, обозначающая, что случайное число будет генерироваться не больше 100. Затем происходит вызов функции на GPU , генерирующей случайное число. Значение будет записываться в переменную result . В главной функции ( main ) происходит инициализация всех значений через вызов GPU , а также здесь происходит работа с памятью – выделение и освобождение. Результатом выполнения программы будет генерация случайного числа:
Сложение векторов в cuda
Технологии для разработки на основе CUDA
Thrust
Thrust [12] — это библиотека параллельных алгоритмов обработки данных на GPU, представленных в виде векторов, с интерфейсом аналогичным C++ Standard Template Library (STL). Thrust удобен возможностью быстро реализовывать необходимые вычислительные алгоритмы в более простой и читаемой форме, чем явное программирование на CUDA. Библиотека уже содержит реализации некоторых базовых алгоритмов (scan, sort и reduce) и позволяет комбинировать их для составления более сложных схем обработки. С другой стороны, Thrust имеет более высокий уровень абстракции, чем CUDA, и не позволяет разработчику непосредственно управлять GPU на низком уровне, например, разделяемой памятью или синхронизацией нитей. Таким образом, Thrust может лучше всего подходить для GPU-приложений, в которых наиболее важную роль играет скорость разработки и надежность.
Thrust входит в состав CUDA Toolkit 4.0, но может быть также установлен отдельно. Сама библиотека состоит только из заголовочных файлов, и необходимые части кода Thrust будут скомпилированы вместе с целевым приложением.
Простейшее преобразование на примере сложения векторов
Пусть необходимо сложить два вектора и поместить результат в третий вектор. На C++ это тривиально реализуется следующим кодом:
for (int i = 0; i ?include Cthrust / transform . h> ?include Cthrust/functional.h> ?include Ciostream>
X[0] = 10; X[l] = 20; X[2] = 30;
Y[0] = 15; Y[l] = 35; Y[2] = 10;
for (size_t i = 0; i — это библиотечный функтор (о функторах речь пойдет далее) операции сложения двух элементов, параметризованный типом float, который применяется к каждой паре элементов X и Y. Аналогично оператору присваивания, оператор «[ ]» реализует копирование данных из памяти GPU в память хоста, что позволяет легко производить поэлементный доступ. Память GPU, занимаемая векторами, будет автоматически освобождена деструктором вектора при выходе за пределы области видимости, содержащей определения.
Сборка приложения, использующего Thrust ничем не отличается от сборки любого CUDA-приложения:
$ nvcc —02 ex01_vector_addition.си —о ex01_vector_addition
Входной файл должен иметь расширение си. Файл с расширением срр, содержащий расширения языка C++, будет сразу передан CPU-компилятору, который скорее всего вернет ошибки компиляции.
CUDA: Как работает GPU
Внутренняя модель nVidia GPU – ключевой момент в понимании GPGPU с использованием CUDA. В этот раз я постараюсь наиболее детально рассказать о программном устройстве GPUs. Я расскажу о ключевых моментах компилятора CUDA, интерфейсе CUDA runtime API, ну, и в заключение, приведу пример использования CUDA для несложных математических вычислений.
Вычислительная модель GPU:
Рассмотрим вычислительную модель GPU более подробно.
- Верхний уровень ядра GPU состоит из блоков, которые группируются в сетку или грид (grid) размерностью N1 * N2 * N3. Это можно изобразить следующим образом:

Рис. 1. Вычислительное устройство GPU.
Размерность сетки блоков можно узнать с помощь функции cudaGetDeviceProperties, в полученной структуре за это отвечает поле maxGridSize. К примеру, на моей GeForce 9600M GS размерность сетки блоков: 65535*65535*1, то есть сетка блоков у меня двумерная (полученные данные удовлетворяют Compute Capability v.1.1).
Рис. 2. Устройство блока GPU.
При использовании GPU вы можете задействовать грид необходимого размера и сконфигурировать блоки под нужды вашей задачи.
CUDA и язык C:
Сама технология CUDA (компилятор nvcc.exe) вводит ряд дополнительных расширений для языка C, которые необходимы для написания кода для GPU:
- Спецификаторы функций, которые показывают, как и откуда буду выполняться функции.
- Спецификаторы переменных, которые служат для указания типа используемой памяти GPU.
- Спецификаторы запуска ядра GPU.
- Встроенные переменные для идентификации нитей, блоков и др. параметров при исполнении кода в ядре GPU .
- Дополнительные типы переменных.
Как было сказано, спецификаторы функций определяют, как и откуда буду вызываться функции. Всего в CUDA 3 таких спецификатора:
- __host__ — выполнятся на CPU, вызывается с CPU (в принципе его можно и не указывать).
- __global__ — выполняется на GPU, вызывается с CPU.
- __device__ — выполняется на GPU, вызывается с GPU.
Спецификаторы запуска ядра служат для описания количества блоков, нитей и памяти, которые вы хотите выделить при расчете на GPU. Синтаксис запуска ядра имеет следующий вид:
myKernelFunc >>(float* param1,float* param2), где
- gridSize – размерность сетки блоков (dim3), выделенную для расчетов,
- blockSize – размер блока (dim3), выделенного для расчетов,
- sharedMemSize – размер дополнительной памяти, выделяемой при запуске ядра,
- cudaStream – переменная cudaStream_t, задающая поток, в котором будет произведен вызов.
Ну и конечно сама myKernelFunc – функция ядра (спецификатор __global__). Некоторые переменные при вызове ядра можно опускать, например sharedMemSize и cudaStream.
Так же стоит упомянуть о встроенных переменных:
- gridDim – размерность грида, имеет тип dim3. Позволяет узнать размер гридa, выделенного при текущем вызове ядра.
- blockDim – размерность блока, так же имеет тип dim3. Позволяет узнать размер блока, выделенного при текущем вызове ядра.
- blockIdx – индекс текущего блока в вычислении на GPU, имеет тип uint3.
- threadIdx – индекс текущей нити в вычислении на GPU, имеет тип uint3.
- warpSize – размер warp’а, имеет тип int (сам еще не пробовал использовать).
Кстати, gridDim и blockDim и есть те самые переменные, которые мы передаем при запуске ядра GPU, правда, в ядре они могут быть read only.
Дополнительные типы переменных и их спецификаторы будут рассмотрены непосредственно в примерах работы с памятью.
CUDA host API:
Перед тем, как приступить к непосредственному использованию CUDA для вычислений, необходимо ознакомиться с так называемым CUDA host API, который является связующим звеном между CPU и GPU. CUDA host API в свою очередь можно разделить на низкоуровневое API под названием CUDA driver API, который предоставляет доступ к драйверу пользовательского режима CUDA, и высокоуровневое API – CUDA runtime API. В своих примерах я буду использовать CUDA runtime API.
В CUDA runtime API входят следующие группы функций:
- Device Management – включает функции для общего управления GPU (получение инфор-мации о возможностях GPU, переключение между GPU при работе SLI-режиме и т.д.).
- Thread Management – управление нитями.
- Stream Management – управление потоками.
- Event Management – функция создания и управления event’ами.
- Execution Control – функции запуска и исполнения ядра CUDA.
- Memory Management – функции управлению памятью GPU.
- Texture Reference Manager – работа с объектами текстур через CUDA.
- OpenGL Interoperability – функции по взаимодействию с OpenGL API.
- Direct3D 9 Interoperability – функции по взаимодействию с Direct3D 9 API.
- Direct3D 10 Interoperability – функции по взаимодействию с Direct3D 10 API.
- Error Handling – функции обработки ошибок.
Понимаем работу GPU:
Как было сказано, нить – непосредственный исполнитель вычислений. Каким же тогда образом происходит распараллеливание вычислений между нитями? Рассмотрим работу отдельно взятого блока.
Задача. Требуется вычислить сумму двух векторов размерностью N элементов.
Нам известна максимальные размеры нашего блока: 512*512*64 нитей. Так как вектор у нас одномерный, то пока ограничимся использованием x-измерения нашего блока, то есть задействуем только одну полосу нитей из блока (рис. 3).
Рис. 3. Наша полоса нитей из используемого блока.
Заметим, что x-размерность блока 512, то есть, мы можем сложить за один раз векторы, длина которых N // Функция сложения двух векторов
__global__ void addVector( float * left, float * right, float * result)
* This source code was highlighted with Source Code Highlighter .
Таким образом, распараллеливание будет выполнено автоматически при запуске ядра. В этой функции так же используется встроенная переменная threadIdx и её поле x, которая позволяет задать соответствие между расчетом элемента вектора и нитью в блоке. Делаем расчет каждого элемента вектора в отдельной нити.
Пишем код, которые отвечает за 1 и 2 пункт в программе:
* This source code was highlighted with Source Code Highlighter .
Для выделения памяти на видеокарте используется функция cudaMalloc, которая имеет следующий прототип:
cudaError_t cudaMalloc( void** devPtr, size_t count ), где
- devPtr – указатель, в который записывается адрес выделенной памяти,
- count – размер выделяемой памяти в байтах.
- cudaSuccess – при удачном выделении памяти
- cudaErrorMemoryAllocation – при ошибке выделения памяти
Для копирования данных в память видеокарты используется cudaMemcpy, которая имеет следующий прототип:
cudaError_t cudaMemcpy(void* dst, const void* src ,size_t count, enum cudaMemcpyKind kind), где
- dst – указатель, содержащий адрес места-назначения копирования,
- src – указатель, содержащий адрес источника копирования,
- count – размер копируемого ресурса в байтах,
- cudaMemcpyKind – перечисление, указывающее направление копирования (может быть cudaMemcpyHostToDevice, cudaMemcpyDeviceToHost, cudaMemcpyHostToHost, cudaMemcpyDeviceToDevice).
- cudaSuccess – при удачном копировании
- cudaErrorInvalidValue – неверные параметры аргумента (например, размер копирования отрицателен)
- cudaErrorInvalidDevicePointer – неверный указатель памяти в видеокарте
- cudaErrorInvalidMemcpyDirection – неверное направление (например, перепутан источник и место-назначение копирования)
Теперь переходим к непосредственному вызову ядра для вычисления на GPU.
…
dim3 gridSize = dim3(1, 1, 1); //Размер используемого грида
dim3 blockSize = dim3(SIZE, 1, 1); //Размер используемого блока
//Выполняем вызов функции ядра
addVector >>(devVec1, devVec2, devVec3);
…
* This source code was highlighted with Source Code Highlighter .
* This source code was highlighted with Source Code Highlighter .
Теперь нам остаеться скопировать результат расчета из видеопамяти в память хоста. Но у функций ядра при этом есть особенность – асинхронное исполнение, то есть, если после вызова ядра начал работать следующий участок кода, то это ещё не значит, что GPU выполнил расчеты. Для завершения работы заданной функции ядра необходимо использовать средства синхронизации, например event’ы. Поэтому, перед копированием результатов на хост выполняем синхронизацию нитей GPU через event.
Код после вызова ядра:
//Выполняем вызов функции ядра
addVector >>(devVec1, devVec2, devVec3);
//Хендл event’а
cudaEvent_t syncEvent;
cudaEventCreate(&syncEvent); //Создаем event
cudaEventRecord(syncEvent, 0); //Записываем event
cudaEventSynchronize(syncEvent); //Синхронизируем event
//Только теперь получаем результат расчета
cudaMemcpy(vec3, devVec3, sizeof ( float ) * SIZE, cudaMemcpyDeviceToHost);
* This source code was highlighted with Source Code Highlighter .
Рассмотрим более подробно функции из Event Managment API.
Event создается с помощью функции cudaEventCreate, прототип которой имеет вид:
cudaError_t cudaEventCreate( cudaEvent_t* event ), где
- *event – указатель для записи хендла event’а.
- cudaSuccess – в случае успеха
- cudaErrorInitializationError – ошибка инициализации
- cudaErrorPriorLaunchFailure – ошибка при предыдущем асинхронном запуске функции
- cudaErrorInvalidValue – неверное значение
- cudaErrorMemoryAllocation – ошибка выделения памяти
Запись event’а осуществляется с помощью функции cudaEventRecord, прототип которой имеет вид:
cudaError_t cudaEventRecord( cudaEvent_t event, CUstream stream ), где
- event – хендл хаписываемого event’а,
- stream – номер потока, в котором записываем (в нашем случае это основной нулевой по-ток).
- cudaSuccess – в случае успеха
- cudaErrorInvalidValue – неверное значение
- cudaErrorInitializationError – ошибка инициализации
- cudaErrorPriorLaunchFailure – ошибка при предыдущем асинхронном запуске функции
- cudaErrorInvalidResourceHandle – неверный хендл event’а
Синхронизация event’а выполняется функцией cudaEventSynchronize. Данная функция ожидает окончание работы всех нитей GPU и прохождение заданного event’а и только потом отдает управление вызывающей программе. Прототип функции имеет вид:
cudaError_t cudaEventSynchronize( cudaEvent_t event ), где
- event – хендл event’а, прохождение которого ожидается.
- cudaSuccess – в случае успеха
- cudaErrorInitializationError – ошибка инициализации
- cudaErrorPriorLaunchFailure – ошибка при предыдущем асинхронном запуске функции
- cudaErrorInvalidValue – неверное значение
- cudaErrorInvalidResourceHandle – неверный хендл event’а
Понять, как работает cudaEventSynchronize, можно из следующей схемы:
Рис. 4. Синхронизация работы основоной и GPU прграмм.
На рисунке 4 блок «Ожидание прохождения Event’а» и есть вызов функции cudaEventSynchronize.
Ну и в заключении выводим результат на экран и чистим выделенные ресурсы.
//Результаты расчета
for ( int i = 0; i «Element #%i: %.1fn» , i , vec3[i]);
>
cudaFree(devVec1);
cudaFree(devVec2);
cudaFree(devVec3);
delete[] vec1; vec1 = 0;
delete[] vec2; vec2 = 0;
delete[] vec3; vec3 = 0;
* This source code was highlighted with Source Code Highlighter .
Думаю, что описывать функции высвобождения ресурсов нет необходимости. Разве что, можно напомнить, что они так же возвращают значения cudaError_t, если есть необходимость проверки их работы.
Заключение
Надеюсь, что этот материал поможет вам понять, как функционирует GPU. Я описал самые главные моменты, которые необходимо знать для работы с CUDA. Попробуйте сами написать сложение двух матриц, но не забывайте об аппаратных ограничениях видеокарты.
Занятие 8. Программирование на CUDA C. Часть 4.
Сложение векторов и сравнение с количеством тредов в памяти
Данный пример довольно прост и демонстрирует реализацию сложения двух векторов, у которых сумма общих нитей не превышает определенное число (в данном случае 10).
Понятное дело, если мы будем использовать N Блоков и 1 тред ( add N , 1 >>>( dev _ a , dev _ b , dev _ c ); ) , то каждый результат с будет равным нулю, кроме первого, поэтому этот код закомментирован, но присутствует в программе в качестве ознакомления с работой блоков и тредов в ядре. В нашем случае результат выполнения программы следующий:
И так до 63 значений, так как подсчет идет с нуля.
Генерация псевдослучайных чисел с использованием CuRand
Генерация псевдослучайных чисел происходит с помощью инструмента curand, который входит в расширение CUDA C.
Библиотека cuRAND предоставляет средства, которые сосредоточены на простой и эффективной генерации псевдослучайных и квазислучайных чисел. cuRAND состоит из двух частей: библиотеки на стороне хоста (CPU) и файла заголовка устройства (GPU). Библиотека на стороне хоста рассматривается как любая другая библиотека: пользователь включает заголовочный файл, #include , чтобы получить объявления функций. Случайные числа могут быть сгенерированы на девайсе или на хосте. Полученные случайные числа сохраняются в глобальной памяти на девайсе. Также пользователь может копировать полученные случайные числа обратно на хост для дальнейшей обработки. Для генерации чисел на хосте вся работа выполняется на хосте, включая их хранение.
Вторая составляющая cuRAND — это заголовочный файл устройства, /include/curand_kernel.h . Этот файл определяет функции генератора случайных чисел. Пользовательский код может включать этот заголовочный файл, а написанные пользователем ядра могут затем вызывать функции устройства, определенные в файле заголовка. Это позволяет создавать случайные числа и немедленно использовать их.
Ниже будет код, демонстрирующий работу данного инструмента:
Как было сказано, первоначально объявляются заголовочные файлы, после чего прописывается стандартная С++ директива define с макросом MAX 100, обозначающая, что случайное число будет генерироваться не больше 100. Затем происходит вызов функции на GPU , генерирующей случайное число. Значение будет записываться в переменную result . В главной функции ( main ) происходит инициализация всех значений через вызов GPU , а также здесь происходит работа с памятью – выделение и освобождение. Результатом выполнения программы будет генерация случайного числа: