Рассмотрим некоторые общие функции линейной алгебры и их применение на чистом Python и numpy. Все примеры — на Jupyter Notebook.
Списки в Python не являются векторами, по умолчанию над ними нельзя производить поэлементные операции.
В Python необходимо определять собственные функции, чтобы оперировать списками как векторами. Для сравнения: в numpy для аналогичных операций достаточно одной строки кода.
- Сложение векторов
- Вычитание векторов
- Скалярное умножение
- Среднее значение вектора
- Скалярное произведение
- Сумма квадратов
- Величина вектора
- Расстояние между двумя векторами
- На заметку
- Нескучный туториал по NumPy
- Что такое NumPy?
- Создание массива
- Доступ к элементам, срезы
- Форма массива и ее изменение
- Перестановка осей и траспонирование
- Объединение массивов
- Клонирование данных
- Математические операции над элементами массива
- Матричное умножение
- Агрегаторы
- Вместо заключения — пример
- Как вы получаете величину вектора в Numpy?
- 5 ответов
Сложение векторов
Но, конечно, в numpy это можно сделать с помощью оператора + на numpy-массивах или с помощью метода sum() .
Вычитание векторов
Скалярное умножение
Среднее значение вектора
Скалярное произведение
Сумма квадратов
Величина вектора
Расстояние между двумя векторами
На заметку
В ряде рассмотренных примеров используется sum() . Чем отличается встроенная Python-функция sum() от numpy.sum() ? Например тем, что numpy.sum() быстрее обрабатывает numpy-массивы, но медленнее Python-списки.
Проверим в Python 2.7.2 и Numpy 1.6.1:
Результат при x = range(1000) :
Результат при x = np.random.standard_normal(1000) :
Согласитесь, имеет смысл учитывать контекст использования.
В основе статьи — материал Бена Алекса Кина. Мой небольшой вклад — перевод, идиоматический код numpy-примеров и дополнительные пояснения.
Нескучный туториал по NumPy
Меня зовут Вячеслав, я хронический математик и уже несколько лет не использую циклы при работе с массивами…
Ровно с тех пор, как открыл для себя векторные операции в NumPy. Я хочу познакомить вас с функциями NumPy, которые чаще всего использую для обработки массивов данных и изображений. В конце статьи я покажу, как можно использовать инструментарий NumPy, чтобы выполнить свертку изображений без итераций (= очень быстро).
Не забываем про
Что такое NumPy?
Это библиотека с открытым исходным кодом, некогда отделившаяся от проекта SciPy. NumPy является наследником Numeric и NumArray. Основан NumPy на библиотеке LAPAC, которая написана на Fortran. Не-python альтернативой для NumPy является Matlab.
В силу того, что NumPy базируется на Fortran это быстрая библиотека. А в силу того, что поддерживает векторные операции с многомерными массивами — крайне удобная.
Кроме базового варианта (многомерные массивы в базовом варианте) NumPy включает в себя набор пакетов для решения специализированных задач, например:
- numpy.linalg — реализует операции линейной алгебры (простое умножение векторов и матриц есть в базовом варианте);
- numpy.random — реализует функции для работы со случайными величинами;
- numpy.fft — реализует прямое и обратное преобразование Фурье.
Итак, я предлагаю рассмотреть подробно всего несколько возможностей NumPy и примеров их использования, которых будет достаточно, чтобы вы поняли, на сколько мощный этот инструмент!
Создание массива
Создать массив можно несколькими способами:
- преобразовать список в массив:
скопировать массив (копия и глубокая копия обязательна. ):
создать нулевой или единичный массив заданного размера:
Либо взять размеры уже существующего массива:
при создании двумерного квадратного массива можете сделать его единичной диагональной матрицей:
построить массив чисел от From (включая) до To (не включая) с шагом Step:
По умолчанию from = 0, step = 1, поэтому возможен вариант с одним параметром, интерпретируемым как To:
Либо с двумя — как From и To:
Обратите внимание, что в методе №3 размеры массива передавались в качестве одного параметра (кортеж размеров). Вторым параметром в способах №3 и №4 можно указать желаемый тип элементов массива:
Используя метод astype, можно привести массив к другому типу. В качестве параметра указывается желаемый тип:
Все доступные типы можно найти в словаре sctypes:
Доступ к элементам, срезы
Доступ к элементам массива осуществляется по целочисленным индексами, начинается отсчет с 0:
Если представить многомерный массив как систему вложенных одномерных массивов (линейный массив, элементы которого могут быть линейными массивами), становится очевидной возможность получать доступ к подмассивам с использованием неполного набора индексов:
С учетом этой парадигмы, можем переписать пример доступа к одному элементу:
При использовании неполного набора индексов, недостающие индексы неявно заменяются списком всех возможных индексов вдоль соответствующей оси. Сделать это явным образом можно, поставив «:». Предыдущий пример с одним индексом можно переписать в следующем виде:
«Пропустить» индекс можно вдоль любой оси или осей, если за «пропущенной» осью последуют оси с индексацией, то «:» обязательно:
Индексы могут принимать отрицательные целые значения. В этом случае отсчет ведется от конца массива:
Можно использовать не одиночные индексы, а списки индексов вдоль каждой оси:
Либо диапазоны индексов в виде «From:To:Step». Такая конструкция называется срезом. Выбираются все элементы по списку индексов начиная с индекса From включительно, до индекса To не включая с шагом Step:
Шаг индекса имеет значение по умолчанию 1 и может быть пропущен:
Значения From и To тоже имеют дефолтные значения: 0 и размер массива по оси индексации соответственно:
Если вы хотите использовать From и To по умолчанию (все индексы по данной оси) а шаг отличный от 1, то вам необходимо использовать две пары двоеточий, чтобы интерпретатор смог идентифицировать единственный параметр как Step. Следующий код «разворачивает» массив вдоль второй оси, а вдоль первой не меняет:
А теперь выполним
Как видите, через B мы изменили данные в A. Вот почему в реальных задачах важно использовать копии. Пример выше должен был бы выглядеть так:
В NumPy также реализована возможность доступа ко множеству элементов массива через булев индексный массив. Индексный массив должен совпадать по форме с индексируемым.
Как видите, такая конструкция возвращает плоский массив, состоящий из элементов индексируемого массива, соответствующих истинным индексам. Однако, если мы используем такой доступ к элементам массива для изменения их значений, то форма массива сохранится:
Над индексирующими булевыми массивами определены логические операции logical_and, logical_or и logical_not выполняющие логические операции И, ИЛИ и НЕ поэлементно:
logical_and и logical_or принимают 2 операнда, logical_not — один. Можно использовать операторы &, | и
для выполнения И, ИЛИ и НЕ соответственно с любым количеством операндов:
Что эквивалентно применению только I1.
Получить индексирующий логический массив, соответсвующий по форме массиву значений можно, записав логическое условие с именем массива в качестве операнда. Булево значение индекса будет рассчитано как истинность выражения для соответствующего элемента массива.
Найдем индексирующий массив I элементов, которые больше, чем 3, а элементы со значениями меньше чем 2 и больше 4 — обнулим:
Форма массива и ее изменение
Многомерный массив можно представить как одномерный массив максимальной длины, нарезанный на фрагменты по длине самой последней оси и уложенный слоями по осям, начиная с последних.
Для наглядности рассмотрим пример:
В этом примере мы из одномерного массива длиной 24 элемента сформировали 2 новых массива. Массив B, размером 4 на 6. Если посмотреть на порядок значений, то видно, что вдоль второго измерения идут цепочки последовательных значений.
В массиве C, размером 4 на 3 на 2, непрерывные значения идут вдоль последней оси. Вдоль второй оси идут последовательно блоки, объединение которых дало бы в результате строки вдоль второй оси массива B.
А учитывая, что мы не делали копии, становится понятно, что это разные формы преставления одного и того же массива данных. Поэтому можно легко и быстро менять форму массива, не изменяя самих данных.
Чтобы узнать размерность массива (количество осей), можно использовать поле ndim (число), а чтобы узнать размер вдоль каждой оси — shape (кортеж). Размерность можно также узнать и по длине shape. Чтобы узнать полное количество элементов в массиве можно воспользоваться значением size:
Обратите внимание, что ndim и shape — это атрибуты, а не методы!
Чтобы увидеть массив одномерным, можно воспользоваться функцией ravel:
Чтобы поменять размеры вдоль осей или размерность используется метод reshape:
Важно, чтобы количество элементов сохранилось. Иначе возникнет ошибка:
Учитывая, что количество элементов постоянно, размер вдоль одной любой оси при выполнении reshape может быть вычислен из значений длины вдоль других осей. Размер вдоль одной оси можно обозначить -1 и тогда он будет вычислен автоматически:
Можно reshape использовать вместо ravel:
Рассмотрим практическое применение некоторых возможностей для обработки изображений. В качестве объекта исследования будем использовать фотографию:

Попробуем ее загрузить и визуализировать средствами Python. Для этого нам понадобятся OpenCV и Matplotlib:
Результат будет такой:

Обратите внимание на строку загрузки:
OpenCV работает с изображениями в формате BGR, а нам привычен RGB. Мы меняем порядок байтов вдоль оси цвета без обращения к функциям OpenCV, используя конструкцию
«[:, :, ::-1]».
Уменьшим изображение в 2 раза по каждой оси. Наше изображение имеет четные размеры по осям, соответственно, может быть уменьшено без интерполяции:
Поменяв форму массива, мы получили 2 новые оси, по 2 значения в каждой, им соответствуют кадры, составленные из нечетных и четных строк и столбцов исходного изображения.
Низкое качество свзано с использованием Matplotlib, за то там видны размеры по осям. На самом деле, качество уменьшенного изображения такое:

Перестановка осей и траспонирование
В кроме изменения формы массива при неизменном порядке единиц данных, часто встречается необходимость изменить порядок следования осей, что естественным образом повлечет перестановки блоков данных.
Примером такого преобразования может быть транспонирование матрицы: взаимозамена строк и столбцов.
В этом примере для транспонирования матрицы A использовалась конструкция A.T. Оператор транспонирования инвертирует порядок осей. Рассмотрим еще один пример с тремя осями:
У этой короткой записи есть более длинный аналог: np.transpose(A). Это более универсальный инструмент для замены порядка осей. Вторым параметром можно задать кортеж номеров осей исходного массива, определяющий порядок их положения в результирующем массиве.
Для примера переставим первые две оси изображения. Картинка должна перевернуться, но цветовую ось оставим без изменения:
Для этого примера можно было применить другой инструмент swapaxes. Этот метод переставляет местами две оси, указанные в параметрах. Пример выше можно было реализовать так:
Объединение массивов
Объединяемые массивы должны иметь одинаковое количество осей. Объединять массивы можно с образованием новой оси, либо вдоль уже существующей.
Для объединения с образованием новой оси исходные массивы должны иметь одинаковые размеры вдоль всех осей:
Как видно из примера, массивы-операнды стали подмассивами нового объекта и выстроились вдоль новой оси, которая стоит самой первой по порядку.
Для объединения массивов вдоль существующей оси, они должны иметь одинаковый размер по всем осям, кроме выбранной для объединения, а по ней могут иметь произвольные размеры:
Для объединения по первой или второй оси можно использовать методы vstack и hstack соответсвенно. Покажем это на примере изображений. vstack объединяет изображения одинаковой ширины по высоте, а hsstack объединяет одинаковые по высоте картинки в одно широкое:
Обратите внимание на то, что во всех примерах этого раздела объединяемые массивы передаются одним параметром (кортежем). Количество операндов может быть любым, а не обязательно только 2.
Также обратите внимание на то, что происходит с памятью, при объединении массивов:
Так как создается новый объект, данные в него копируются из исходных массивов, поэтому изменения в новых данных не влияют на исходные.
Клонирование данных
Оператор np.repeat(A, n) вернет одномерный массив с элементами массива A, каждый из которых будет повторен n раз.
После этого преобразования, можно перестроить геометрию массива и собрать повторяющиеся данные в одну ось:
Этот вариант отличается от объединения массива с самим собой оператором stack только положением оси, вдоль которой стоят одинаковые данные. В примере выше это последняя ось, если использовать stack — первая:
Как бы ни было выполнено клонирование данных, следующим шагом можно переместить ось, вдоль которой стоят одинаковые значения, в любую позицию с системе осей:
Если же мы хотим «растянуть» какую либо ось, используя повторение элементов, то ось с одинаковыми значениями надо поставить после растягиваемой (используя transpose), а затем объединить эти две оси (используя reshape). Рассмотрим пример с растяжением изображения вдоль вертикальной оси за счет дублирования строк:
Математические операции над элементами массива
Если A и B массивы одинакового размера, то их можно складывать, умножать, вычитать, делить и возводить в степень. Эти операции выполняются поэлементно, результирующий массив будет совпадать по геометрии с исходными массивами, а каждый его элемент будет результатом выполнения соответствующей операции над парой элементов из исходных массивов:
Можно выполнить любую операцию из приведенных выше над массивом и числом. В этом случае операция также выполнится над каждым из элементов массива:
Учитывая, что многомерный массив можно рассматривать как плоский массив (первая ось), элементы которого — массивы (остальные оси), возможно выполнение рассматриваемых операций над массивами A и B в случае, когда геометрия B совпадает с геометрией подмассивов A при фиксированном значении по первой оси. Иными словами, при совпадающем количестве осей и размерах A[i] и B. Этом случае каждый из массивов A[i] и B будут операндами для операций, определенных над массивами.
В этом примере массив B подвергается операции с каждой строкой массива A. При необходимости умножения/деления/сложения/вычитания/возведения степень подмассивов вдоль другой оси, необходимо использовать транспонирование, чтобы поставить нужную ось на место первой, а затем вернуть ее на свое место. Рассмотри пример выше, но с умножением на вектор B столбцов массива A:
Для более сложных функций (например, для тригонометрических, экспоненты, логарифма, преобразования между градусами и радианами, модуля, корня квадратного и.д.) в NumPy есть реализация. Рассмотрим на примере экспоненты и логарифма:
С полным списком математических операций в NumPy можно ознакомиться тут.
Матричное умножение
Описанная выше операция произведения массивов выполняется поэлементно. А при необходимости выполнения операций по правилам линейной алгебры над массивами как над тензорами можно воспользоваться методом dot(A, B). В зависимости от вида операндов, функция выполнит:
- если аргументы скаляры (числа), то выполнится умножение;
- если аргументы вектор (одномерный массив) и скаляр, то выполнится умножение массива на число;
- если аргументы вектора, то выполнится скалярное умножение (сумма поэлементных произведений);
- если аргументы тензор (многомерный массив) и скаляр, то выполнится умножение вектора на число;
- если аргументы тензора, то выполнится произведение тензоров по последней оси первого аргумента и предпоследней — второго;
- если аргументы матрицы, то выполнится произведение матриц (это частный случай произведения тензоров);
- если аргументы матрица и вектор, то выполнится произведение матрицы и вектора (это тоже частный случай произведения тензоров).
Для выполнения операций должны совпадать соответсвующие размеры: для векторов длины, для тензоров — длины вдоль осей, по которым будет происходить суммирование поэлементных произведений.
Рассмотрим примеры со скалярами и векторами:
С тензорами посмотрим только на то, как меняется размер геометрия результирующего массива:
Для выполнения произведения тензоров с использованием других осей, вместо определенных для dot можно воспользоваться tensordot с явным указанием осей:
Мы явно указали, используем третью ось первого массива и вторую — второго (размеры по этим осям должны совпадать).
Агрегаторы
Агрегаторы — это методы NumPy позволяющие заменять данные интегральными характеристиками вдоль некоторых осей. Например, можно посчитать среднее значение, максимальное, минимальное, вариацию или еще какую-то характеристику вдоль какой-либо оси или осей и сформировать из этих данных новый массив. Форма нового массива будет содержать все оси исходного массива, кроме тех, вдоль которых подсчитывался агрегатор.
Для примера, сформируем массив со случайными значениями. Затем найдем минимальное, максимальное и среднее значение в его столбцах:
При таком использовании mean и average выглядят синонимами. Но эти функции обладают разным набором дополнительных параметров. У нах разные возможности по маскированию и взвешиванию усредняемых данных.
Можно подсчитать интегральные характеристики и по нескольким осям:
В этом примере рассмотрена еще одна интегральная характеристика sum — сумма.
Список агрегаторов выглядит примерно так:
- сумма: sum и nansum — вариант корректно обходящийся с nan;
- произведение: prod и nanprod;
- среднее и матожидание: average и mean (nanmean),
nanaverageнету; - медиана: median и nanmedian;
- перцентиль: percentile и nanpercentile;
- вариация: var и nanvar;
- стандартное отклонение (квадратный корень из вариации): std и nanstd;
- минимальное значение: min и nanmin;
- максимальное значение: max и nanmax;
- индекс элемента, имеющего минимальное значение: argmin и nanargmin;
- индекс элемента, имеющего максимальное значение: argmax и nanargmax.
В случае использования argmin и argmax (соответственно, и nanargmin, и nanargmax) необходимо указывать одну ось, вдоль которой будет считаться характеристика.
Если не указать оси, то по умолчанию все рассматриваемые характеристики считаются по всему массиву. В этом случае argmin и argmax тоже корректно отработают и найдут индекс максимального или минимального элемента так, как буд-то все данные в массиве вытянуты вдоль одной оси командой ravel().
Еще следует отметить, агрегирующие методы определены не только как методы модуля NumPy, но и для самих массивов: запись np.aggregator(A, axes) эквивалентна записи A.aggregator(axes), где под aggregator подразумевается одна из рассмотренных выше функций, а под axes — индексы осей.
Вместо заключения — пример
Давайте построим алгоритм линейной низкочастотной фильтрации изображения.
Для начала загрузим зашумленное изображение.
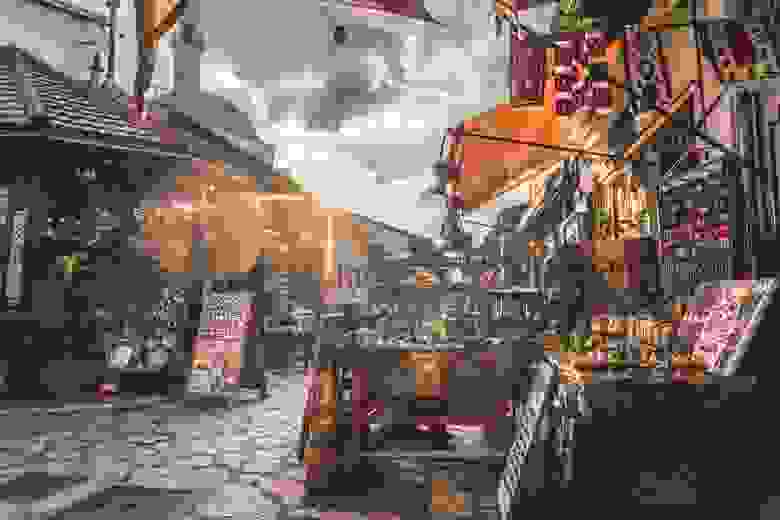
Рассмотрим фрагмент изображения, чтобы увидеть шум:
Фильтровать изображение будем с использованием гауссова фильтра. Но вместо выполнения свертки непосредственно (с итерированием), применим взвешенное усреднение срезов изображения, сдвинутых относительно друг друга:
Применим эту функцию к нашему изображению единожды, дважды и трижды:
Получаем следующие результаты:
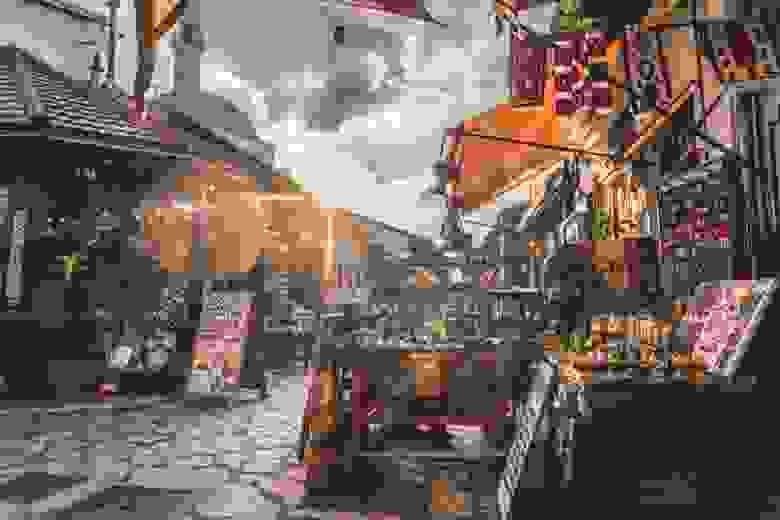
при однократном применении фильтра;
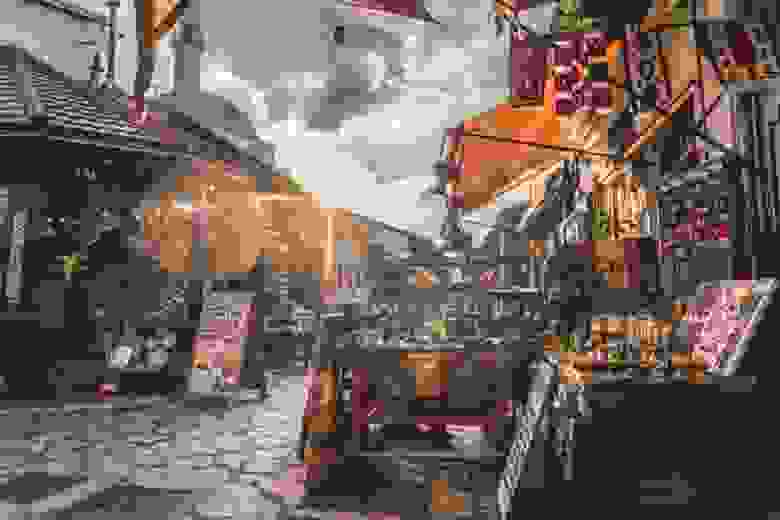
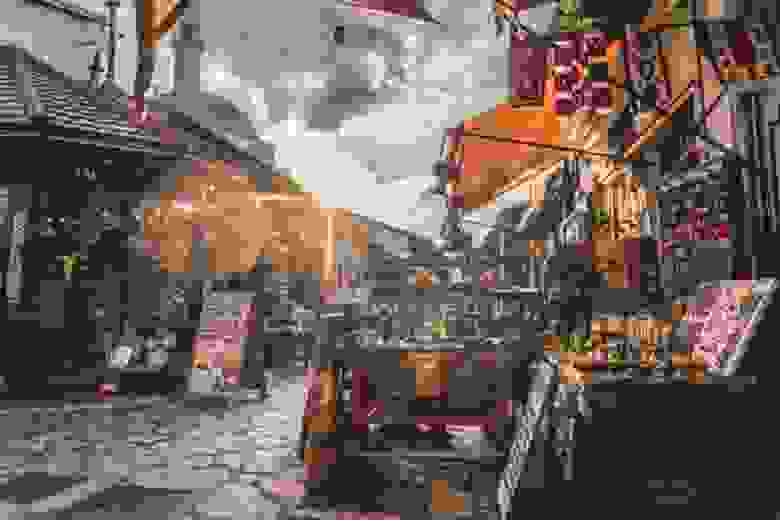
Видно, что с повышением количества проходов фильтра снижается уровень шума. Но при этом снижается и четкость изображения. Это известная проблема линейных фильтров. Но наш метод денойзинга изображения не претендует на оптимальность: это лишь демонстрация возможностей NumPy реализации свертки без итераций.
Теперь давайте посмотрим, сверткам с какими ядрами эквивалентна наша фильтрация. Для этого подвергнем аналогичным преобразованиям одиночный единичный импульс и визуализируем. На самом деле импульс будет не единичным, а равным по амплитуде 255, так как само смешивание оптимизировано под целочисленные данные. Но это не мешает оценить общий вид ядер:
Мы рассмотрели далеко не полный набор возможностей NumPy, надеюсь, этого было достаточно для демонстрации всей мощи и красоты этого инструмента!
Как вы получаете величину вектора в Numpy?
в соответствии с «Есть только один очевидный способ сделать это», как вы получаете величину вектора (1D массива) в Numpy?
выше работает, но я не верю что я должен сам указать такую тривиальную и основную функцию.
5 ответов
функции вы после numpy.linalg.norm . (Я считаю, что он должен быть в base numpy как свойство массива-скажем x.norm() — ну да ладно).
вы также можете кормить в дополнительный ord для энного нормой порядке. Скажем, вы хотели 1-норму:
Если вы беспокоитесь о скорости, вы должны использовать:
вот некоторые ориентиры:
EDIT: реальное улучшение скорости происходит, когда вам нужно взять норму многих векторов. Использование чистых функций numpy не требует никаких циклов. Например:
еще одна альтернатива-использовать einsum функция в numpy для любых массивов:
однако, похоже, есть некоторые накладные расходы, связанные с его вызовом, которые могут замедлить его с небольшими входами:
самый быстрый способ, который я нашел, — через inner1d. Вот как он сравнивается с другими методами numpy:
3x быстрее, чем linalg.норма и волос быстрее, чем эйнсум