Сервис RusVectōrēs вычисляет семантические отношения между словами русского языка и позволяет скачать предобученные дистрибутивно-семантические модели (word embeddings), в том числе контекстуализированные. Он назван по аналогии с RusCorpora, веб-сайтом Национального Корпуса Русского Языка (НКРЯ). На RusCorpora можно работать с корпусами (лат. corpora), а на нашем ресурсе — с лексическими векторами (лат. vectōrēs). Они представляют значение слова, автоматически извлеченное из статистики совместной встречаемости слов в корпусах (больших коллекциях текстовых данных).
В дистрибутивной семантике слова обычно представляются в виде векторов в многомерном пространстве их контекстов. Семантическое сходство вычисляется как косинусная близость между векторами двух слов и может принимать значения в промежутке [-1. 1] (на практике часто используются только значения выше 0). Значение 0 приблизительно означает, что у этих слов нет похожих контекстов и их значения не связаны друг с другом. Значение 1, напротив, свидетельствует о полной идентичности их контекстов и, следовательно, о близком значении.
Дистрибутивная семантика лежит в основе почти всех современных систем автоматической обработки языка. В основном используются векторные модели, обученные на больших корпусах: это так называемые word embedding models (часто для их обучения применяют простые искуственные нейронные сети на основе предсказания следующего слова: language modeling). В результате семантика слов представляется сжатыми векторами, которые можно использовать для самых разных компьютерно-лингвистических задач. Один из первых и наиболее известный на сегодня инструмент в этой области — word2vec, но регулярно появляются новые алгоритмы и модели.
К сожалению, обучение дистрибутивных моделей на основе больших корпусов может требовать существенных вычислительных мощностей. Поэтому важно предоставить русскоязычному лингвистическому сообществу доступ к предобученным моделям. Наш сервис дает пользователям готовые модели для скачивания (чтобы продолжить эксперименты на своём компьютере), а также удобный интерфейс запросов к ним. Также возможно визуализировать семантические отношения между словами, что, как мы надеемся, будет полезным для исследователей. В целом, задача нашего сервиса — снизить порог входа для тех, кто хочет работать в этом новом и интересном направлении.
- Возможности RusVectōrēs
- Ссылки
- Публикации
- Избранные статьи о дистрибутивной семантике
- Избранные публикации, использующие RusVectōrēs
- Цитирование
- Navec — компактные эмбеддинги для русского языка
- RusVectores
- Качество
- Принцип работы
- Квантизация
- Использование
- Обзор четырёх популярных NLP-моделей 🙊 💬
- furry.cat
- 1. Рекуррентная нейросетевая языковая модель (RNNLM)
- Готовые модели
- Преимущества
- Недостатки
- 2. Word2vec
- Векторная магия
- Готовые модели
- Преимущества
- Недостатки
- 3. GloVe (Global Vectors)
- Готовые модели
- Преимущества
- Недостатки
- 4. fastText
- Готовые модели
- Преимущества
- Недостатки
Возможности RusVectōrēs
RusVectōrēs — это инструмент, который позволяет исследовать отношения между словами в дистрибутивных моделях. Можно образно назвать наш сервис «семантическим калькулятором». Пользователь может выбрать одну или несколько из тщательно подготовленных моделей, обученных на разных корпусах.
Выбрав модель, вы можете:
- вычислять семантическое сходство между парами слов;
- находить слова, ближайшие к данному (с возможностью фильтрации по части речи и частотности);
- решать аналогии вида «найти слово X, которое так относится к слову Y, как слово A относится к слову B»;
- выполнять над векторами слов алгебраические операции (сложение, вычитание, поиск центра лексического кластера и расстояний до этого центра).
- рисовать семантические карты отношений между словами (это позволяет выявлять семантические кластеры или тестировать ваши гипотезы о таких кластерах);
- получать вектор (в виде массива чисел) и его визуализацию для данного слова в выбранной модели: для этого нужно кликнуть по любому слову или использовать уникальный адрес этого слова, как описано ниже;
- генерировать контекстно-зависимые лексические подстановки для контекстуализированных дистрибутивных моделей, например, ELMo;
- скачать модель.
В духе парадигмы Semantic Web, каждое слово каждой модели обладает своим уникальным идентификатором URI, явно указывающим лемму, модель и часть речи (например, https://rusvectores.org/ru/ruscorpora_upos_cbow_300_20_2019/алгоритм_NOUN/). По запросу на этот адрес генерируется список десяти слов, ближайших к данной лемме в данной модели и принадлежащих к той же части речи, что и сама лемма, а также другая информация о слове, например, его вектор в виде массива чисел.
Также у сервиса есть API, с помощью которого можно для любого слова получить список слов, семантически близких к данному в выбранной модели (одной из доступных для работы через веб-интерфейс). Данные можно получить в двух форматах: json и csv. Для этого необходимо выполнить GET-запрос по адресу следующего вида: https://rusvectores.org/MODEL/WORD/api/FORMAT/, где MODEL — идентификатор для выбранной модели, WORD — слово запроса, FORMAT — «csv» или «json» по вашему выбору. По запросу отдаётся файл в формате json или текстовый файл в формате tab-separated values, в котором перечислены ближайшие десять соседей слова.
Кроме того, можно получать значения семантической близости для пар слов в любой из моделей. Формат запроса: https://rusvectores.org/MODEL/WORD1__WORD2/api/similarity/ (обратите внимание на 2 знака подчеркивания между словами).
Алгебраические операции над векторами дают интересные результаты и предоставляют простор для экспериментов. Например, модель, обученная на Национальном корпусе русского языка, возвращает слово быт в результате вычитания слова любовь из слова жизнь .
Естественно, можно сравнивать результаты разных моделей.
Кроме веб-интерфейса, для нашего сервиса также доступен бот в мессенджере Telegram. С помощью бота можно делать запросы к API, не выходя из любимого мессенджера! Это может быть удобно для лингвистических экспериментов по дороге на работу/учёбу, или в любой другой ситуации, когда хочется быстро проверить идею, а компьютера под рукой нет. Также вы можете подписаться на наш Telegram-канал.
Нам бы хотелось, чтобы RusVectōrēs стал одним из узлов академической информации о дистрибутивных моделях для русского языка, поэтому на сайте имеется раздел «Публикации», содержащий опубликованные научные работы и ссылки на другие полезные ресурсы. В то же время, мы надеемся, что RusVectōrēs популяризует дистрибутивную семантику и компьютерную лингвистику и сделает их более доступными и привлекательными для русскоязычной публики.
Ссылки
Этот сервис работает на WebVectors, свободном и открытом фреймворке для работы с векторными семантическими моделями через Интернет. Статья о WebVectors.
Тьюториал, в котором описана предобработка корпусов, базовые операции над векторами слов в модели, обращение к API RusVectōrēs (всё с готовым кодом на Python).
Публикации
Избранные статьи о дистрибутивной семантике
- Turney, P. D., P. Pantel. From frequency to meaning: Vector space models of semantics. Journal of artificial intelligence research, 37(1), 141-188. (2010)
- Mikolov, T., et al. Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781 (2013).
- Mikolov, Tomas, et al. Exploiting similarities among languages for machine translation. arXiv preprint arXiv:1309.4168 (2013).
- Baroni, Marco, et al. Don’t count, predict! A systematic comparison of context-counting vs. context-predicting semantic vectors. Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics. Vol. 1. (2014)
- Pennington, J., et al. Glove: Global Vectors for Word Representation. EMNLP. Vol. 14. 2014.
- Le, Quoc., and Mikolov, Tomas. Distributed representations of sentences and documents. Proceedings of the 31st International Conference on Machine Learning (2014).
- Kutuzov, Andrey and Kuzmenko, Elizaveta. Comparing Neural Lexical Models of a Classic National Corpus and a Web Corpus: The Case for Russian. A. Gelbukh (Ed.): CICLing 2015, Part I, Springer LNCS 9041, pp. 47–58, 2015. DOI: 10.1007/978-3-319-18111-0_4
- Bartunov Sergey et al. Breaking Sticks and Ambiguities with Adaptive Skip-gram. Eprint arXiv:1502.07257, 02/2015
- O. Levy, Y. Goldberg, and I. Dagan Improving Distributional Similarity with Lessons Learned from Word Embeddings. TACL 2015
- Xin Rong word2vec Parameter Learning Explained. arXiv preprint arXiv:1411.2738 (2015)
- Panchenko A., et al. RUSSE: The First Workshop on Russian Semantic Similarity. Proceedings of the Dialogue 2015 conference, Moscow, Russia (2015)
- Kutuzov, Andrey and Andreev, Igor. Texts in, meaning out: neural language models in semantic similarity task for Russian. Proceedings of the Dialog 2015 Conference, Moscow, Russia (2015)
- Arefyev N.V., et al. Evaluating three corpus-based semantic similarity systems for Russian. Proceedings of the Dialogue 2015 conference, Moscow, Russia (2015)
- Lopukhin K.A., et al. The impact of different vector space models and supplementary techniques in Russian semantic similarity task. Proceedings of the Dialogue 2015 conference, Moscow, Russia (2015)
- Hamilton, W. L., et al. Diachronic Word Embeddings Reveal Statistical Laws of Semantic Change. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (2016).
- Sahlgren, M., and Lenci, A. The Effects of Data Size and Frequency Range on Distributional Semantic Models. Proceedings of EMNLP. (2016)
- Bojanowski, P., et al. Enriching Word Vectors with Subword Information. Transactions of the Association of Computational Linguistics – Volume 5, Issue 1 (2017).
- Peters, M., et al. Deep Contextualized Word Representations. Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (2018).
Доклад Андрея Кутузова «Дистрибутивно-семантические модели языка и их применение» на семинаре в Институте системного анализа РАН 3 марта 2017:
Избранные публикации, использующие RusVectōrēs
- Bolshina, A., Loukachevitch N. Automatic Labelling of Genre-Specific Collections for Word Sense Disambiguation in Russian. Proceedings of 18th Russian Conference on Artificial Intelligence (2020)
- Gudkov, V., et al. Russian Prepositional Phrase Semantic Labeling with Word Embedding-Based Classifier. Proceedings of the III International Conference on Language Engineering and Applied Linguistics (2019)
- Larionov, D., et al. Semantic Role Labeling with Pretrained Language Models for Known and Unknown Predicates. Proceedings of the International Conference on Recent Advances in Natural Language Processing (RANLP 2019)
- Bogolyubova, O., et al. The Language of Positive Mental Health: Findings from a Sample of Russian Facebook Users. SAGE Open 10, no. 2 (2020)
- Loukachevitch, N., and Rusnachenko, N. Distant SUpervision for Sentiment Attitude Extraction. Proceedings of the International Conference on Recent Advances in Natural Language Processing (RANLP 2019)
- Zheng, X., et al. Semantic Role Labeling for Russian Language Based on Ensemble Model. IEEE 8th Joint International Information Technology and Artificial Intelligence Conference (2019)
- Mrkšić, N. et al. Semantic Specialisation of Distributional Word Vector Spaces using Monolingual and Cross-Lingual Constraints. Transactions of the Association for Computational Linguistics (TACL) (2018)
- Bogolyubova, O., et al. Dark Personalities on Facebook: Harmful Online Behaviors and Language. Computers in Human Behavior, Volume 78 (2018)
- Antropova, O., et al. Cleaning Up After a Party: Post-processing Thesaurus Crowdsourced Data. Conference on Artificial Intelligence and Natural Language. Springer, Cham (2018)
- Loukachevitch, N., Rusnachenko, N. Extracting Sentiment Attitudes from Analytical Texts. Dialogue conference (2018)
- Rusnachenko, N., Loukachevitch, N. Sentiment Attitudes and Their Extraction from Analytical Texts. International Workshop on Temporal, Spatial, and Spatio-Temporal Data Mining. Springer, Cham (2018)
- Enikeeva, E., Popov, A. Developing a Russian Database of Regular Semantic Relations Based on Word Embeddings. The XVIII EURALEX International Congress (2018).
- Pronoza, E., et al. Extraction of Typical Client Requests from Bank Chat Logs. Mexican International Conference on Artificial Intelligence. Springer, Cham (2018)
- Ermilov, A., et al. Stierlitz Meets SVM: Humor Detection in Russian. Conference on Artificial Intelligence and Natural Language. Springer, Cham (2018)
- Badryzlova, Y., Panicheva, P. A Multi-feature Classifier for Verbal Metaphor Identification in Russian Texts. Conference on Artificial Intelligence and Natural Language. Springer, Cham (2018)
- Karyaeva, M., et al. Extraction of Hypernyms from Dictionaries with a Little Help from Word Embeddings. International Conference on Analysis of Images, Social Networks and Texts. Springer, Cham (2018)
- Sboev, A., et al. Automatic gender identification of author of Russian text by machine learning and neural net algorithms in case of gender deception. Procedia Computer Science 123 (2018)
- Panicheva, P., Badryzlova, Yu. Distributional semantic features in Russian verbal metaphor identification. Komp’juternaja Lingvistika i Intellektual’nye Tehnologii, Volume 1, Issue 16 (2017)
- Trofimov, I., Suleymanova, E. A syntax-based distributional model for discriminating between semantic similarity and association. Komp’juternaja Lingvistika i Intellektual’nye Tehnologii, Volume 1, Issue 16 (2017)
- Shelmanov, A., Devyatkin, D. Semantic role labeling with neural networks for texts in Russian. Komp’juternaja Lingvistika i Intellektual’nye Tehnologii, Volume 1, Issue 16 (2017)
- Enikeeva I., Mitrofanova, O. Russian Collocation extraction based on word embeddings. Komp’juternaja Lingvistika i Intellektual’nye Tehnologii, Volume 1, Issue 16 (2017)
- Bolotova, V., et al. Which IR model has a better sense of humor? Search over a large collection of jokes. Komp’juternaja Lingvistika i Intellektual’nye Tehnologii, Volume 1, Issue 16 (2017)
- Anh, L., et al. Application of a Hybrid Bi-LSTM-CRF model to the task of Russian Named Entity Recognition. Conference on Artificial Intelligence and Natural Language. Springer, Cham (2017)
- Кузнецов, И. Автоматическая разметка семантических ролей в русском языке. Диссертация на соискание ученой степени кандидата филологических наук (2016) (in Russian)
- Кириллов, А. Н., Крижановский. А. А. Модель геометрической структуры синсета. Серия «Математическое моделирование и информационные технологии», Вып. 08, стр. 45-54, 2016 (in Russian)
- Kalimoldayev, M., et al. The application of the connectionist method of semantic similarity for Kazakh language. In Electronics Computer and Computation (ICECCO), 2015 Twelve International Conference on (pp. 1-3). IEEE.
- Kopotev, M., Pivovarova, L., & Kormacheva, D. Constructional generalization over Russian collocations. Memoires de la Societe neophilologique de Helsinki, 2016
- .
Цитирование
Если вы используете RusVectōrēs в своей научной работе, пожалуйста, процитируйте эту статью:
Kutuzov A., Kuzmenko E. (2017) WebVectors: A Toolkit for Building Web Interfaces for Vector Semantic Models. In: Ignatov D. et al. (eds) Analysis of Images, Social Networks and Texts. AIST 2016. Communications in Computer and Information Science, vol 661. Springer, Cham (pdf, bibtex)
Мы благодарим компанию nlogic за помощь в хостинге RusVectōrēs.
Navec — компактные эмбеддинги для русского языка
Библиотека Navec — часть проекта Natasha, коллекция предобученных эмбеддингов для русского языка. Качество решения сравнимо или выше, чем у статических моделей от RusVectores, размер в 5–6 раз меньше:
| Качество | Размер модели, МБ | Размер словаря, ×10 3 | |
|---|---|---|---|
| Navec | 0.719 | 50.6 | 500 |
| RusVectores | 0.638–0.726 | 220.6–290.7 | 189–249 |
В этой статье поговорим про старые добрые пословные эмбеддинги, совершившие революцию в NLP в 2013 году.
python − счастье + страдание = perl
Технология актуальна до сих пор. В проекте Natasha модели для разбора морфологии, синтаксиса и извлечения именованных сущностей работают на пословных Navec-эмбеддингах, показывают качество выше других открытых решений.
RusVectores
Для русского языка принято использовать предобученные эмбеддинги от RusVectores, у них есть неприятная особенность: в таблице записаны не слова, а пары «слово_POS-тег». Идея хорошая, для пары «печь_VERB» ожидаем вектор, похожий на «готовить_VERB», «варить_VERB», а для «печь_NOUN» — «изба_NOUN», «топка_NOUN».
На практике использовать такие эмбеддинги неудобно. Недостаточно разделить текст на токены, для каждого нужно как-то определить POS-тег. Таблица эмбеддингов разбухает. Вместо одного слова «стать», мы храним 6: 2 разумных «стать_VERB», «стать_NOUN» и 4 странных «стать_ADV», «стать_PROPN», «стать_NUM», «стать_ADJ». В таблице на 250 000 записей 195 000 уникальных слов.
Качество
Оценим качество эмбеддингов на задаче семантической близости. Возьмём пару слов, для каждого найдём вектор-эмбеддинг, посчитаем косинусное сходство. Navec для похожих слов «чашка» и «кувшин» возвращет 0.49, для «фрукт» и «печь» — −0.0047. Соберём много пар с эталонными метками похожести, посчитаем корреляцию Спирмена с нашими ответами.
Кроме семантической близости для оценки качества эмбеддингов используют задачу решения аналогий. RusVectores публикует переведённый датасет Google Analogies. Прогнать на нём Navec пока не дошли руки.
Авторы RusVectores используют небольшой аккуратно проверенный и исправленный тестовый список пар SimLex965. Добавим свежий яндексовый LRWC и датасеты из проекта RUSSE: HJ, RT, AE, AE2:
| Среднее качество на 6 датасетах | Время загрузки, секунды | Размер модели, МБ | Размер словаря, ×10 3 | ||
|---|---|---|---|---|---|
| Navec | hudlit_12B_500K_300d_100q | 0.719 | 1.0 | 50.6 | 500 |
| news_1B_250K_300d_100q | 0.653 | 0.5 | 25.4 | 250 | |
| RusVectores | ruscorpora_upos_cbow_300_20_2019 | 0.692 | 3.3 | 220.6 | 189 |
| ruwikiruscorpora_upos_skipgram_300_2_2019 | 0.691 | 5.0 | 290.0 | 248 | |
| tayga_upos_skipgram_300_2_2019 | 0.726 | 5.2 | 290.7 | 249 | |
| tayga_none_fasttextcbow_300_10_2019 | 0.638 | 8.0 | 2741.9 | 192 | |
| araneum_none_fasttextcbow_300_5_2018 | 0.664 | 16.4 | 2752.1 | 195 |
Качество hudlit_12B_500K_300d_100q сравнимо или лучше, чем у решений RusVectores, словарь больше в 2–3 раза, размер модели меньше в 5–6 раз. Как удалось получить такое качество и размер?
Принцип работы
Почему не word2vec? Эксперименты на большом датасете быстрее с GloVe. Один раз считаем матрицу коллокаций, по ней готовим эмбеддинги разных размерностей, выбираем оптимальный вариант.
Почему не fastText? В проекте Natasha мы работаем с текстами новостей. В них мало опечаток, проблему OOV-токенов решает большой словарь. 250 000 строк в таблице news_1B_250K_300d_100q покрывают 98% слов в новостных статьях.
Статья Давида Дале про компактный предобученный fastText для русского языка: Как сжать модель fastText в 100 раз
Размер словаря hudlit_12B_500K_300d_100q — 500 000 записей, он покрывает 98% слов в художественных текстах. Оптимальная размерность векторов — 300. Таблица 500 000 × 300 из float-чисел занимает 578МБ, размер архива с весами hudlit_12B_500K_300d_100q в 12 раз меньше (48МБ). Дело в квантизации.
Квантизация
Заменим 32-битные float-числа на 8-битные коды: [−∞, −0.86) — код 0, [−0.86, -0.79) — код 1, [-0.79, -0.74) — 2, …, [0.86, ∞) — 255. Размер таблицы уменьшится в 4 раз (143МБ):
Данные огрубляются, разные значения -0.005 и -0.003 заменяет один код 127, -0.030 и -0.031 — 118
Заменим кодом не одно, а 3 числа. Кластеризуем все тройки чисел из таблицы эмбеддингов алгоритмом k-means на 256 кластеров, вместо каждой тройки будем хранить код от 0 до 255. Таблица уменьшится ещё в 3 раза (48МБ). Navec использует библиотеку PQk-means, она разбивает матрицу на 100 колонок, каждую кластеризует отдельно, качество на синтетических тестах падёт на 1 процентный пункт.
Понятно про квантизацию в статье Chris McCormick Product Quantizers for k-NN Tutorial
Квантованные эмбеддинги проигрывают обычным по скорости. Сжатый вектор перед использованием нужно распаковать. Аккуратно реализуем процедуру, применим Numpy-магию, в PyTorch используем torch.gather . В Slovnet NER доступ к таблице эмбеддингов занимает 0.1% от общего времени вычислений.
Использование
Модуль NavecEmbedding из библиотеки Slovnet интегрирует Navec в PyTorch-модели:

Лаборатория разрабатывает сервисы и коробочные продукты с использованием технологии Natasha, оказывает услуги анализа данных для российских компаний.
Обзор четырёх популярных NLP-моделей 🙊 💬

furry.cat
Одна из задач языкового моделирования – предсказать следующее слово, опираясь на знание предыдущего текста. Это нужно для исправления опечаток, автодополнения, чат-ботов и т. д. В интернете можно найти много разрозненной информации о моделях обработки естественного языка. Мы собрали четвёрку популярных NLP-моделей в одном месте и сравнили их, опираясь на документацию и научные источники.
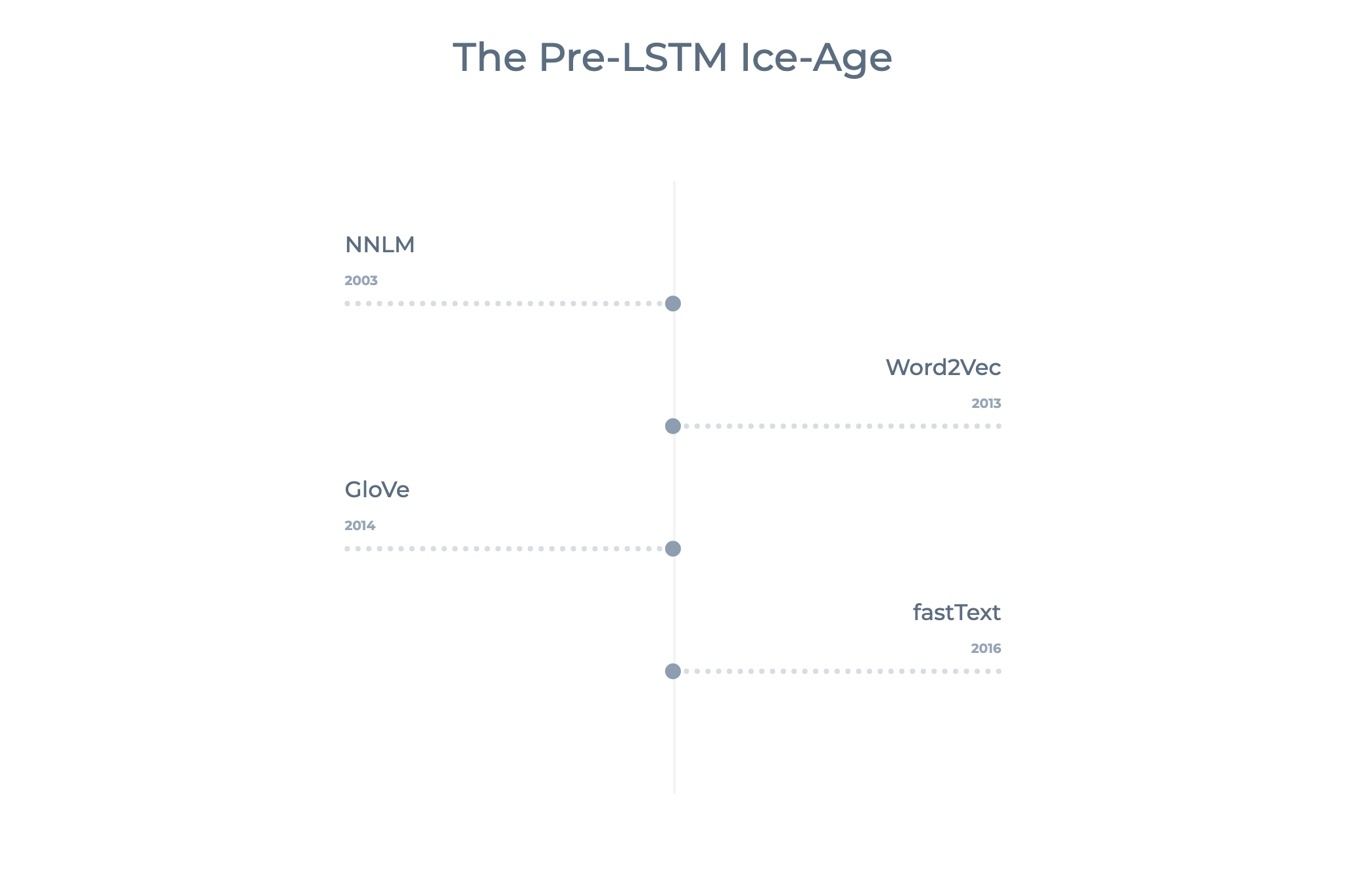 Временная шкала, выделяющая четыре описываемые модели
Временная шкала, выделяющая четыре описываемые модели
1. Рекуррентная нейросетевая языковая модель (RNNLM)
Возникшая в 2001 г. идея привела к рождению одной из первых embedding-моделей.
Модель принимает на вход векторные представления n предыдущих слов и может «понимать» семантику предложения. Обучение модели базируется на алгоритме непрерывного мешка слов. Контекстные (соседние) слова подаются на вход нейронной сети, которая предсказывает центральное слово.
Сжатые векторы объединяются, передаются в скрытый слой, где срабатывает softmax функция активации, определяющая, какие сигналы пройдут дальше (если эта тема вызывает трудности, прочитайте наше Наглядное введение в нейросети).
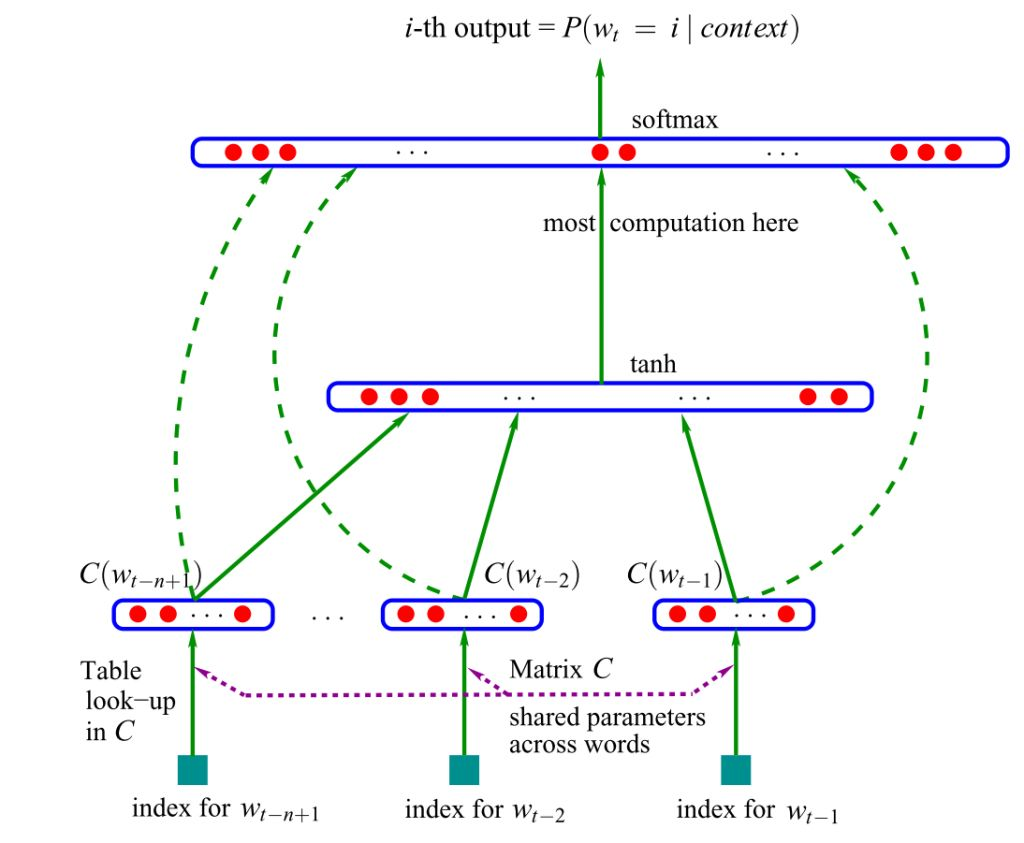 Схема нейронной языковой модели прямого распространения
Схема нейронной языковой модели прямого распространения
Оригинальная версия основывалась на нейросетях прямого распространения – сигнал шёл строго от входного слоя к выходному. Позднее была предложена альтернатива в виде рекуррентных нейронных сетей (RNN) – именно на «ванильной» RNN, а не на управляемых рекуррентных блоках (GRUs) или на долгой краткосрочной памяти (LSTM).
Готовые модели
У Google есть предварительно обученные open-source модели для большинства языков (английская версия). Модель использует три скрытых слоя нейронной сети прямого распространения, обучена на корпусе English Google News 200B и генерирует 128-мерный эмбеддинг.
Преимущества
- Простота. Модель быстро обучается и генерирует эмбеддинги, что достаточно для большинства простых приложений.
- Предварительно обученные версии доступны на многих языках.
Недостатки
- Не учитывает долгосрочные зависимости.
- Простота ограничивает возможности использования.
- Новые embeddings модели намного мощнее.
Источник: Yoshua Bengio, Réjean Ducharme, Pascal Vincent, Christian Jauvin, A Neural Probabilistic Language Model (2003), Journal of Machine Learning Research
2. Word2vec
В 2013 году Томас Миколов (Tomas Mikolov) из Google предложил более эффективную модель обучения векторных представлений слов – Word2vec. Метод основывался на предположении, что слова, которые часто находятся в одинаковых контекстах, имеют схожие значения. Изменения были просты – устранение скрытого слоя и аппроксимация (упрощение) цели – но стали поворотной точкой в развитии языковых моделей NLP.
Вместо алгоритма непрерывного мешка слов модель Word2Vec использует Skip-gram (словосочетание с пропуском). Цель этой модели прямо противоположная предыдущей модели – предсказать окружающие слова на основе центрального.
Чтобы сделать обучение эффективнее, используется негативное семплирование (Negative Sampling): модели предоставляются слова, которые не являются контекстными соседями.
Векторная магия
Модель Word2vec поразила исследователей своей «интерпретируемостью». Обучение на больших корпусах текстов позволяет определять глубокие отношения между формами слов, например, гендерные. Если из вектора, соответствующего слову Мужчина (Man) вычесть вектор Женщина (Woman), результат будет очень похож на разность векторов Король (King) и Королева (Queen).
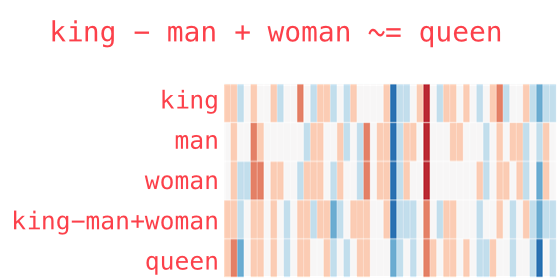
Одно время такое отношения между словами и их векторами казалось почти магией. Ещё несколько забавных примеров векторной арифметики вы можете найти в статье Во что превращается жизнь без любви. Несмотря на огромный вклад, который модель внесла в NLP, сейчас она почти не используется – на смену пришли достойные наследники.
Готовые модели
Предварительно обученная модель легко доступна в интернете. В Python-проект её можно импортировать с помощью библиотеки gensim.
Преимущества
- Простая архитектура: feed-forward, 1 вход, 1 скрытый слой, 1 выход.
- Модель быстро обучается и генерирует эмбеддинги (даже ваши собственные).
- Эмбеддинги наделены смыслом, спорные моменты поддаются расшифровке.
- Методология может быть распространена на множество других областей/проблем (например, Lda2vec).
Недостатки
- Обучение на уровне слов: нет информации о предложении или контексте, в котором используется слово.
- Совместная встречаемость игнорируется. Модель не учитывает то, что слово может иметь различное значение в зависимости от контекста использования. Это основная причина, по которой GloVe обычно предпочтительнее Word2Vec.
- Не очень хорошо обрабатывает неизвестные и редкие слова.
Источник: Tomas Mikolov, Kai Chen, Greg Corrado, Jeffrey Dean, Efficient Estimation of Word Representations in Vector Space (2013), International Conference on Learning Representations
3. GloVe (Global Vectors)
GloVe тесно ассоциируется с Word2Vec: алгоритмы появились примерно в одно и то же время и опираются на интерпретируемость векторов слов. Модель GloVe пытается решить проблему эффективного использования статистики совпадений. GloVe минимизирует разницу между произведением векторов слов и логарифмом вероятности их совместного появления с помощью стохастического градиентного спуска. Полученные представления отражают важные линейные подструктуры векторного пространства слов: получается связать вместе разные спутники одной планеты или почтовый код города с его названием.
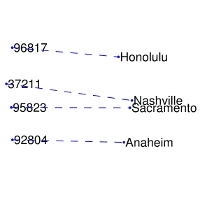 Связь названия города и его почтового кода
Связь названия города и его почтового кода
В Word2Vec частота совместной встречаемости слов не имеет большого значения, она лишь помогает генерировать дополнительные обучающие выборки. GloVe учитывает совместную встречаемость, а не полагается только на контекстную статистику. Векторы слов группируются вместе на основе их глобальной схожести.
Готовые модели
Преимущества
- Простая архитектура без нейронной сети.
- Модель быстрая, и этого может быть достаточно для простых приложений.
- GloVe улучшает Word2Vec. Она добавляет частоту встречаемости слов и опережает Word2Vec на большинстве бенчмарков.
- Осмысленные эмбеддинги.
Недостатки
- Хотя матрица совместной встречаемости предоставляет глобальную информацию, GloVe остаётся обученной на уровне слов и даёт немного данных о предложении и контексте, в котором слово используется.
- Плохо обрабатывает неизвестные и редкие слова.
Источник: Jeffrey Pennington, Richard Socher, and Christopher D. Manning, GloVe: Global Vectors for Word Representation (2014), Empirical Methods in Natural Language Processing
4. fastText
Созданная в Facebook библиотека fastText – ещё один серьёзный шаг в развитии моделей естественного языка. В её разработке принял участие Томас Миколов, уже знакомый нам по Word2Vec. Для векторизации слов используются одновременно и skip-gram, и негативное семплирование, и алгоритм непрерывного мешка.
К основной модели Word2Vec добавлена модель символьных n-грамм. Каждое слово представляется композицией нескольких последовательностей символов определённой длины. Например, слово they в зависимости от гиперпараметров может состоять из «th», «he», «ey», «the», «hey». По сути, вектор слова – это сумма всех его n-грамм.
Результаты работы классификатора хорошо подходят для слов с небольшой частотой встречаемости, так как они разделяются на n-граммы. В отличие от Word2Vec и Glove, модель способна генерировать эмбеддинги для неизвестных слов.
Готовые модели
В сети доступна подготовленная модель для 157 языков (в том числе русского).
Преимущества
- Относительно простая архитектура: feed-forward, 1 вход, 1 скрытый слой, один выход (хотя n-граммы добавляют сложность в генерацию эмбеддингов).
- Благодаря n-граммам неплохо работает на редких и устаревших словах.
Недостатки
- Обучение на уровне слов: нет информации о предложении или контексте, в котором используется слово.
- Игнорируется совместная встречаемость, то есть модель не учитывает различное значение слова в разных контекстах (поэтому GloVe может быть предпочтительнее).
Источник: Armand Joulin, Edouard Grave, Piotr Bojanowski and Tomas Mikolov, Bag of Tricks for Efficient Text Classification (2016), European Chapter of the Association for Computational Linguistics
Все четыре модели имеют много общего, но каждая из них должна использоваться в подходящем контексте. К сожалению, этот момент часто игнорируется, что приводит к получению неоптимальных результатов.
Если вам интересна тема обработки естественного языка, у нас есть ещё пара материалов: